付付
站长
本站致力于分享与传播互联网创业相关的知识内容,包括站长原创录制的教程以及通过公开渠道合法采集整理的网络创业类课程资料。
免责声明:
版权保护:
感谢您的理解与支持,共同营造良好的网络创业学习环境!
大家好,我是付付,微信:ffiexmw 公众号:付付创业研究院
今天要给大家分享的是付付自己开发的一个 Openai TTS 文本转语音小工具。之前研究数字人律师时接触过 Openai TTS ,囿于找不到合适的软件调用服务,索性自己写了个~
软件第一版公布到了我的另一个网站上,发现还是有很多人下载的。正好后面接了一个相关的单子,所以在第一版的基础上进一步完善了,加入了新功能。正好“付付项目网”上了正轨,就将这个软件对接了一下网站分享给大家:
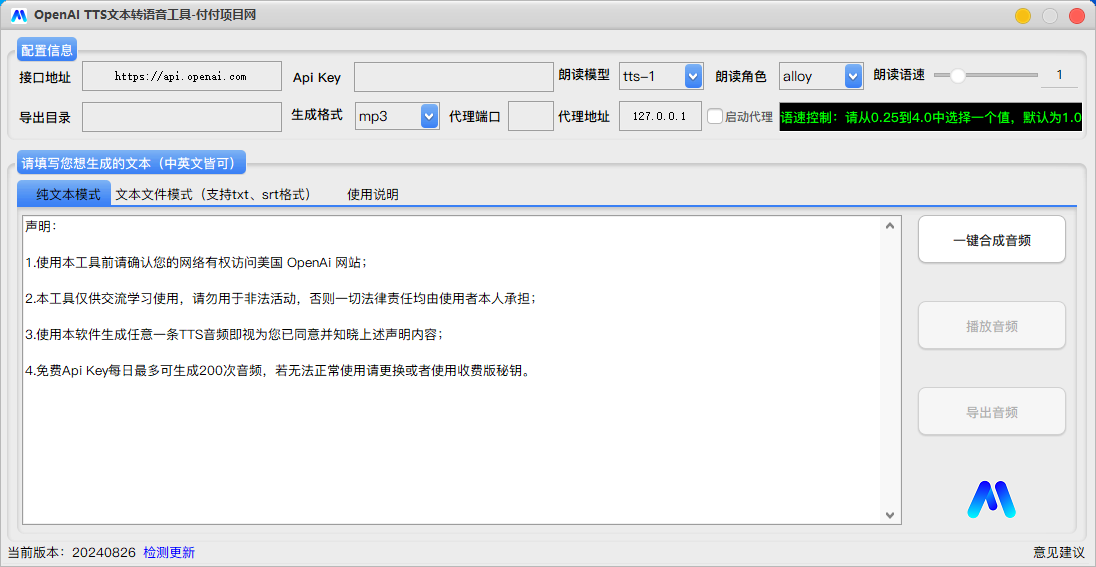
软件界面
付付项目网 OpenAi TTS 文本转语音工具是基于 Openai TTS API 开发的一款 Windows 本地文本转语音软件,用户只需要简单的配置即可将文本转成音频,免去安装各种环境支持的烦恼。Openai TTS是基于先进的深度学习技术开发的文本转语音系统。它能够将文本信息转换为流畅自然、接近人声的语音输出。
Openai TTS 针对其两个音频生成模型模型提供了以下两种计费方式:
TTS-1 $0.015 / 1K characters
TTS-1-HD $0.030 / 1K characters
不过 OpenAi api 新账号注册即送五美金额度,如果只用 tts-1 模型的话,大概可以生成 33 万字符。使用完了之后可以重新注册账号,几乎等于免费使用。
在我目前所接触过的商用TTS模型当中,Openai 生成的语音是最接近真人的,相对其他模型其听起来更加自然、流畅,能够很好地模仿人类的语音模式,包括语调、停顿、强调等。唯一美中不足的是中文发音有时候会有港腔或者是外国人腔调,但瑕不掩瑜。
第一个版本仅支持简单的文本转语音,且单个语音字数有一定限制,优化完善之后支持:
之前:因为 Tokens 限制的问题,最长只能支持1000字左右的文本转为音频。
现在:优化了写法,理论上可不限字数生成,实测10000+字数稳定输出!但建议还是不要太长,防止网络中断啥的造成 Tokens 浪费!
可以单独/批量添加或批量扫描文件文档后一键批量生成语音;
支持全部导入后单个文档操作:生成、导出、删除等;
支持输出文件到原文档目录。
网络环境必须可以访问 Openai 网站[后文有解决方案];
只支持 Windows 平台使用[跨平台开发我真不会啊]!!!

接口地址、Api Key
· 官&方:https://api.openai.com
· 第三方:https://xxx.xxx.xx
官方秘钥获取地址:https://platform.openai.com/api-keys
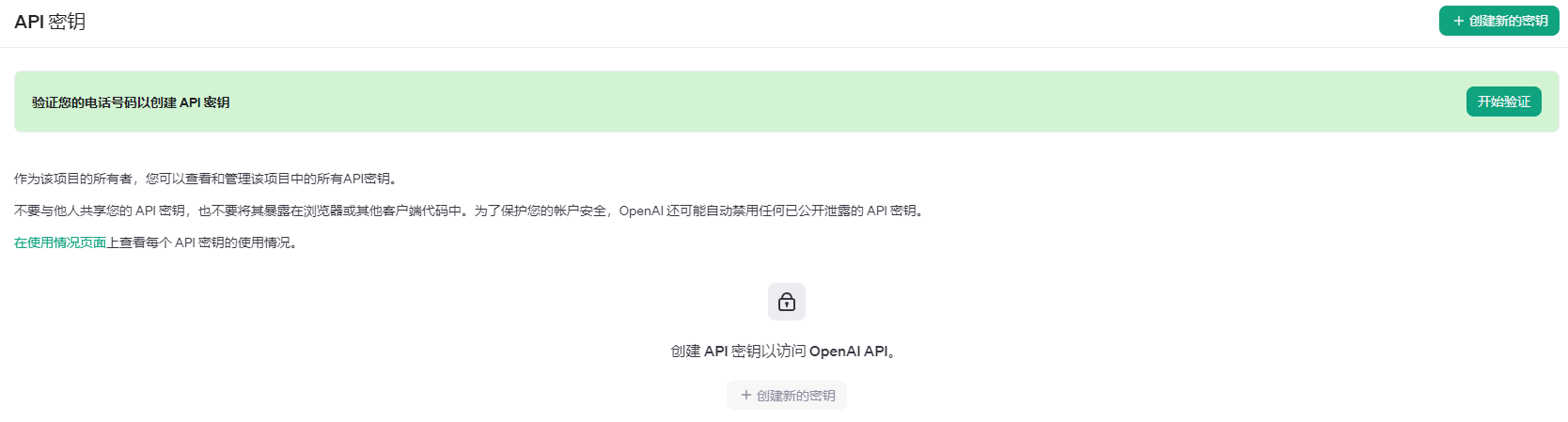
官方秘钥创建
新注册的账号新建秘钥需要境外电话认证,无法直接创建Api key!解决方案如图示:
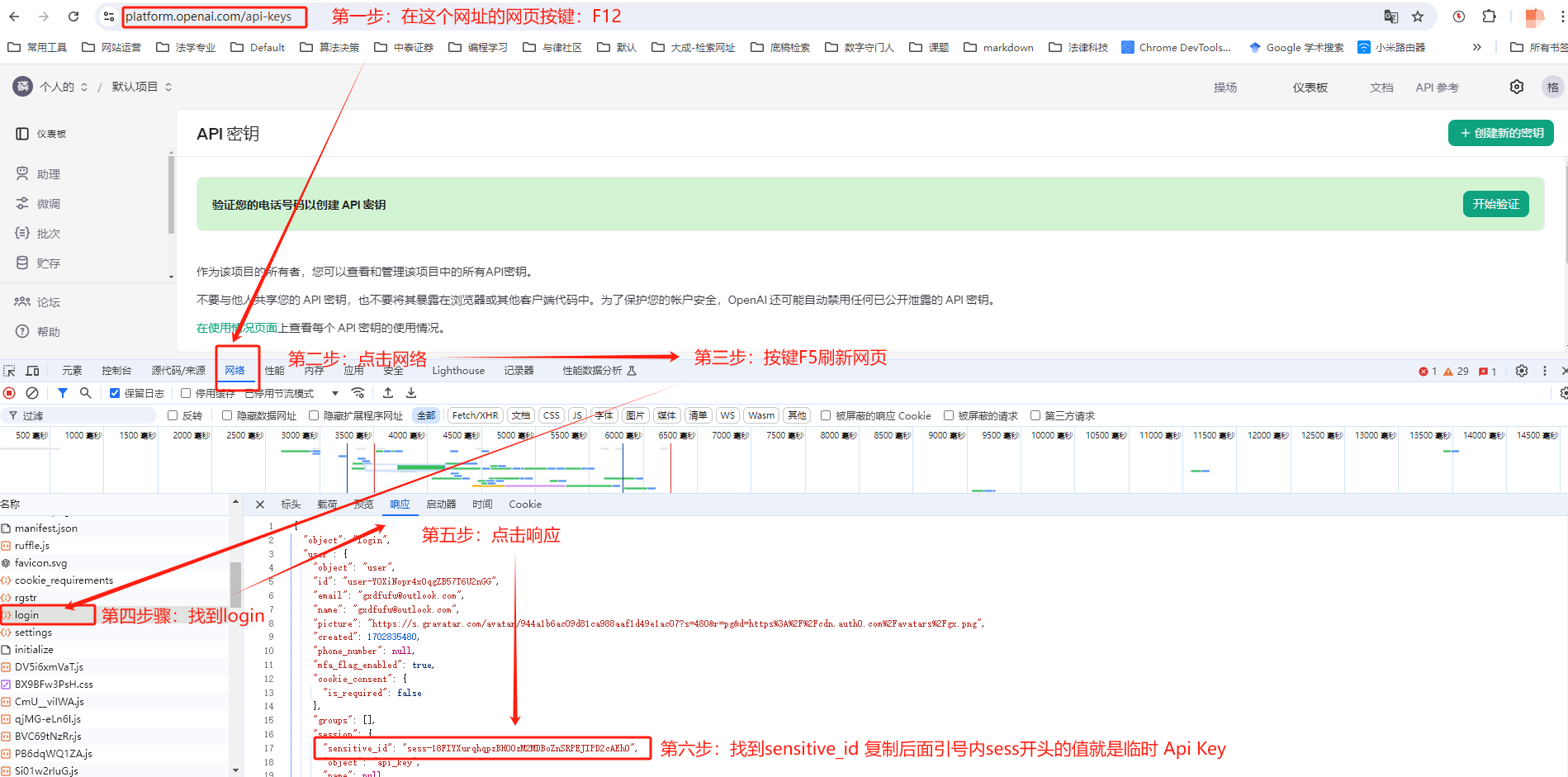
临时 Api Key 获取教程
白嫖怪有话说: Openai Api 新账号会有五美金的调用额度,差不多可以生成几十万字的音频。所以,如果没有境外手机号认证且也不想那个那个的话,可以通过注册多个账号获取临时秘钥使用,个人场景差不多也够了。(个人还是建议付费使用的哈~)
已经完成电话认证的,直接创建秘钥或者复制以前的秘钥填写即可。
使用第三方秘钥: 注意请与第三方接口保持一致!
填入秘钥后,软件会将秘钥数据保存至本地软件数据目录,下次启动后会自动读取,不用每次都填写。
主要包括模型、发音角色、语速、响应格式、导出目录以及代理。
模型选择:模型有 tts-1 和 tts-1-hd 两种选择,一个生成更快,一个音频质量更高,但实测没什么区别;tts-1-hd 价格贵两倍;
发音角色:OpenAi TTS 提供了六个选项,alloy、echo、fable、onyx、nova、shimmer;
语速设置:只能是 0.25-4.0 之间的值,默认1.0,有需求可以放心大胆的调整,乱输也不会出错;
输出格式:默认是mp3,大家也可以根据自己的需要选择opus、aac或flac等,没有特别需求默认mp3即可,其他格式生成完成后不支持播放; opus:主要用于互联网流媒体和通信,低延迟;aac:主要用于数字音频压缩,YouTube、Android、iOS 首选;flac:主要用于无损音频压缩。
导出目录:默认导出到桌面;
代理访问:部分电脑可能魔法环境不彻底,会导致软件无法生成;此时可以获取魔法软件的代理ip和端口填入软件即可正常使用。不懂可以问我!
双击文本框为自动清除声明文本,直接手动输入或者粘贴你需要转换成语音的文本即可。
输入文本
· 点击添加文件:添加一个或者多个特定的TXT、SRT文本文档;
· 点击扫描文件:添加文件夹内所有TXT、SRT文本文档到软件。
输入文本后,点击右侧的 一键合成音频 等待几秒钟即生成完成。
待“显示台”提示生成完成后,播放音频 和导出音频按钮会解锁,如果生成的是mp3格式的音频,则点击播放音频即可听到刚刚生成的文本音频,试听无误后可以导出音频到指定目录。
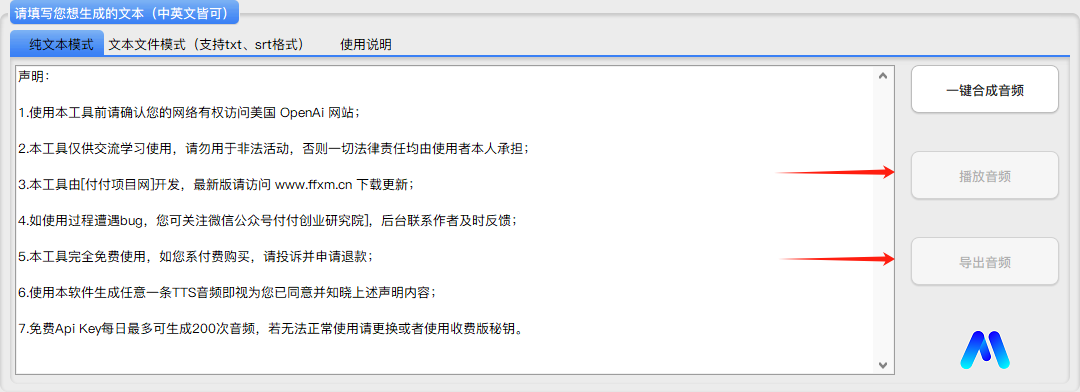
文本模式生成导出
导出的文件名为当前日期时间.格式,如20240128170155.mp3
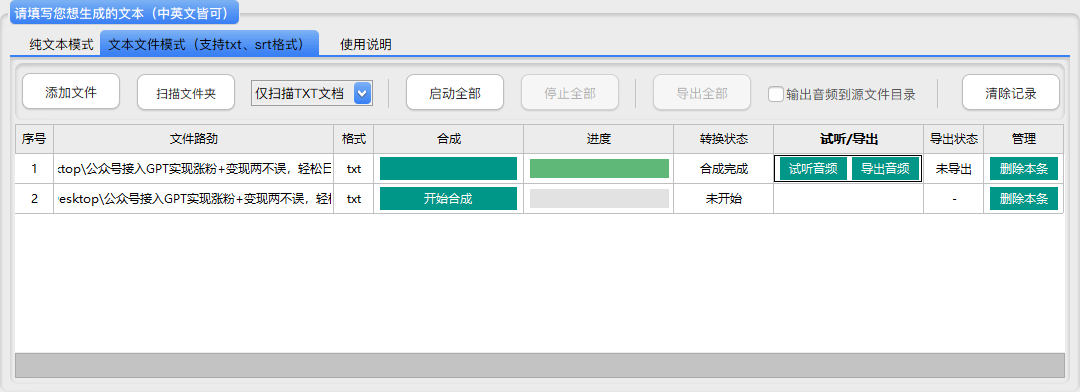
文档模式生成导出
启动全部:将软件内所有文档均生成音频;
停止全部:停止所有正在进行的音频生成;
导出全部:将生成完成的音频导出到设置目录;
输出音频文本到源文件目录:生成的音频直接存储到文本文档存放目录;
清除记录:删除所有音频生成记录;
表内·开始合成:开始合成单个文档文本内容音频;
表内·取消合成:取消合成单个文档文本内容音频;
表内·试听音频:试听单个文档文本内容生成音频;
表内·停止播放:停止播放单个文档文本内容生成的音频;
表内·导出音频:导出单个文档文本内容生成的音频到设置目录;
表内·删除本条:删除单个文档TTS记录;
导出的文件名为文档文件名称.格式,如测试文档.mp3
TTS 技术的应用非常广泛,比如教育领域、新闻媒体领域、企业客服、个人日常阅读等等。但当前最广泛的应用还是自媒体短视频的配音生产:相较于目前主流的一些 TTS 配音工具,OpenAi TTS 配音更加拟人化,听感更好且更有特色。
当然,市面上也有一些更加优秀的 TTS 模型,如GPT-SoVITS、ChatTTS等,不仅可以定制音色,在语调上也更接近真人。但是存在一定使用门槛,依赖本地推理可能比较吃配置先不说,光部署可能就会将大多数人拦在门外。